
{kind=link}
The NotebookLM is a comparatively new Web phenomenon, wherein Google has distinguished itself, due to its Audio Overview mode – a mechanism that transforms the textual content within the paper right into a two-person podcast. All of this, in a single click on. However what must you do while you want to construct it your self and don’t need to use proprietary black packing containers – mainly, full management of the knowledge? Enter NotebookLlama.
NotebookLlama is a free-source implementation of the Meta suggestion, which recreates the podcast expertise of the notebookLM utilizing Llama fashions. This information may also information you in the direction of assembling a whole functioning NotebookLlama pipeline by utilizing Python, Groq (safer inference at asthond toen velocity) and open-source fashions.
This text reveals a clear, publish-ready implementation you may really ship. You’ll go from PDF to a elegant MP3 utilizing:
- PDF textual content extraction
- A quick mannequin for cleansing (low cost and fast)
- An even bigger mannequin for scriptwriting (extra inventive)
- Groq’s text-to-speech endpoint to generate practical audio
The Total Workflow
The workflow of this NotebookLlama venture may be damaged down into 4 levels. All levels refine the content material, remodeling a tough textual content into a whole audio file.
- PDF Pre-processing: The uncooked textual content is first bought out of the supply PDF. The primary is often unclean and unstructured textual content.
- Textual content Cleansing: Second, we clear the textual content with the help of a quick and environment friendly AI mannequin, Llama 3.1. It eliminates oddities, formatting issues and unwarranted particulars.
- Scriptwriting Podcast: A bigger, extra inventive template is utilized to the clear textual content to make one of many two audio system discuss to the opposite. One speaker is an professional, and the opposite is the one who poses curious questions.
- Audio Technology: Our final step in a text-to-speech engine is to have an audio modified based mostly on the textual content per line of script. We may have totally different voices per speaker and blend the audio samples collectively to create one MP3 file.
Let’s start constructing this PDF-to-podcast pipeline.
What you’ll construct
Enter: any text-based PDF
Output: an MP3 file which reads as a pure dialogue between two individuals in an precise dialog with its personal voices and pure rhythm.
Design objectives:
- No black field: each step outputs recordsdata you may examine.
- Restartable: If or when step 4 fails, you don’t restart steps 1 to three.
- Structured outputs: we use strict JSON so your pipeline doesn’t break when the mannequin will get “inventive”.
Conditions
Palms-on Implementation: From PDF to Podcast
This half can be a step-by-step tutorial with all of the code and explanations for the 4 levels described above. We can be explaining the NotebookLlama workflow right here and also will present full executable code recordsdata in the long run.
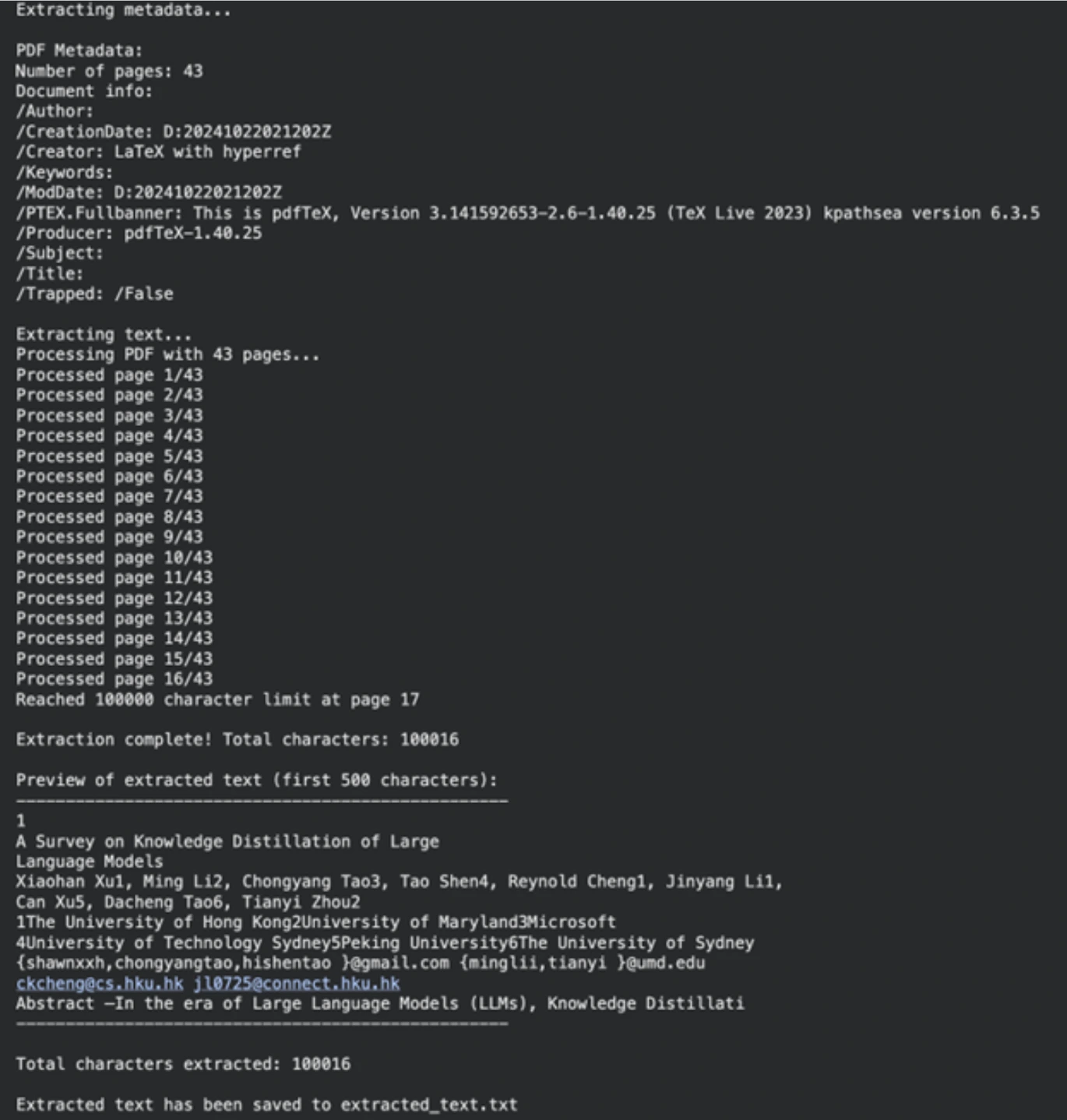
Our first job is to get the textual content content material out of our supply doc. The PyPF2 library can be used to do that. This library is ready to course of PDF paperwork properly.
Set up Dependencies
First, set up the required Python libraries. The command accommodates the utilities for studying PDF recordsdata, textual content processing, and communication with the AI fashions.
!uv pip set up PyPDF2 wealthy ipywidgets langchain_groqSubsequent, we outline the trail to our PDF file (may be any PDF; we used a analysis paper). The following operate will verify the presence of the file and the truth that it belongs to PDF. Then extracttextfrompdf reads the doc web page by web page and retrieves the textual content. We had a personality restrict to make the method manageable.
import os
from typing import Elective
import PyPDF2
pdf_path = "/content material/2402.13116.pdf" # Path to your PDF file
def validate_pdf(file_path: str) -> bool:
if not os.path.exists(file_path):
print(f"Error: File not discovered at path: {file_path}")
return False
if not file_path.decrease().endswith(".pdf"):
print("Error: File is just not a PDF")
return False
return True
def extract_text_from_pdf(file_path: str, max_chars: int = 100000) -> Elective[str]:
if not validate_pdf(file_path):
return None
strive:
with open(file_path, "rb") as file:
pdf_reader = PyPDF2.PdfReader(file)
num_pages = len(pdf_reader.pages)
print(f"Processing PDF with {num_pages} pages...")
extracted_text = []
total_chars = 0
for page_num in vary(num_pages):
web page = pdf_reader.pages[page_num]
textual content = web page.extract_text()
if not textual content:
proceed
if total_chars + len(textual content) > max_chars:
remaining_chars = max_chars - total_chars
extracted_text.append(textual content[:remaining_chars])
print(f"Reached {max_chars} character restrict at web page {page_num + 1}")
break
extracted_text.append(textual content)
total_chars += len(textual content)
final_text = "n".be a part of(extracted_text)
print(f"nExtraction full! Complete characters: {len(final_text)}")
return final_text
besides Exception as e:
print(f"An sudden error occurred: {str(e)}")
return None
extracted_text = extract_text_from_pdf(pdf_path)
if extracted_text:
output_file = "extracted_text.txt"
with open(output_file, "w", encoding="utf-8") as f:
f.write(extracted_text)
print(f"nExtracted textual content has been saved to {output_file}")Output
Step 2: Cleansing Textual content with Llama 3.1
Uncooked textual content from PDFs is usually messy. It might embody undesirable line breaks, mathematical expressions, and different formatting items. Moderately than making a code of legal guidelines to wash this, we will use a machine studying mannequin. On this job, we are going to use llama-3.1-8b-instant, which is a quick and highly effective mannequin that’s preferrred for this exercise.
Outline the Cleansing Immediate
A system immediate is used to show the mannequin. This command instructs the AI to be an automatic textual content pre-processor. It requests the mannequin to get rid of irrelevant info and provides again clear textual content that’s match for a podcast creator.
SYS_PROMPT = """
You're a world class textual content pre-processor, right here is the uncooked information from a PDF, please parse and return it in a approach that's crispy and usable to ship to a podcast author.
The uncooked information is tousled with new strains, Latex math and you will note fluff that we will take away utterly. Principally take away any particulars that you just suppose may be ineffective in a podcast creator's transcript.
Keep in mind, the podcast could possibly be on any subject by any means so the problems listed above are usually not exhaustive
Please be good with what you take away and be inventive okay?
Keep in mind DO NOT START SUMMARIZING THIS, YOU ARE ONLY CLEANING UP THE TEXT AND RE-WRITING WHEN NEEDED
Be very good and aggressive with eradicating particulars, you'll get a operating portion of the textual content and hold returning the processed textual content.
PLEASE DO NOT ADD MARKDOWN FORMATTING, STOP ADDING SPECIAL CHARACTERS THAT MARKDOWN CAPATILISATION ETC LIKES
ALWAYS begin your response instantly with processed textual content and NO ACKNOWLEDGEMENTS about my questions okay?
Right here is the textual content:
"""Chunk and Course of the Textual content
There’s an higher context restrict for giant language fashions. We aren’t in a position to digest the entire doc concurrently. We will divide the textual content into items. So as to forestall halving of phrases, we don’t chunk in character rely however somewhat in phrase rely.
The create_word_bounded_chunks operate splits our textual content into manageable items.
def create_word_bounded_chunks(textual content, target_chunk_size):
phrases = textual content.break up()
chunks = []
current_chunk = []
current_length = 0
for phrase in phrases:
word_length = len(phrase) + 1
if current_length + word_length > target_chunk_size and current_chunk:
chunks.append(" ".be a part of(current_chunk))
current_chunk = [word]
current_length = word_length
else:
current_chunk.append(phrase)
current_length += word_length
if current_chunk:
chunks.append(" ".be a part of(current_chunk))
return chunksAt this level, we are going to configure our mannequin and deal with every chunk. Groq is used to run the Llama 3.1 mannequin, which may be very quick when it comes to velocity of inference.
from langchain_groq import ChatGroq
from langchain_core.messages import HumanMessage, SystemMessage
from tqdm.pocket book import tqdm
from google.colab import userdata
# Setup Groq shopper
GROQ_API_KEY = userdata.get("groq_api")
chat_model = ChatGroq(
groq_api_key=GROQ_API_KEY,
model_name="llama-3.1-8b-instant",
)
# Learn the extracted textual content file
with open("extracted_text.txt", "r", encoding="utf-8") as file:
text_to_clean = file.learn()
# Create chunks
chunks = create_word_bounded_chunks(text_to_clean, 1000)
# Course of every chunk
processed_text = ""
output_file = "clean_extracted_text.txt"
with open(output_file, "w", encoding="utf-8") as out_file:
for chunk in tqdm(chunks, desc="Processing chunks"):
messages = [
SystemMessage(content=SYS_PROMPT),
HumanMessage(content=chunk),
]
response = chat_model.invoke(messages)
processed_chunk = response.content material
processed_text += processed_chunk + "n"
out_file.write(processed_chunk + "n")
out_file.flush()Output
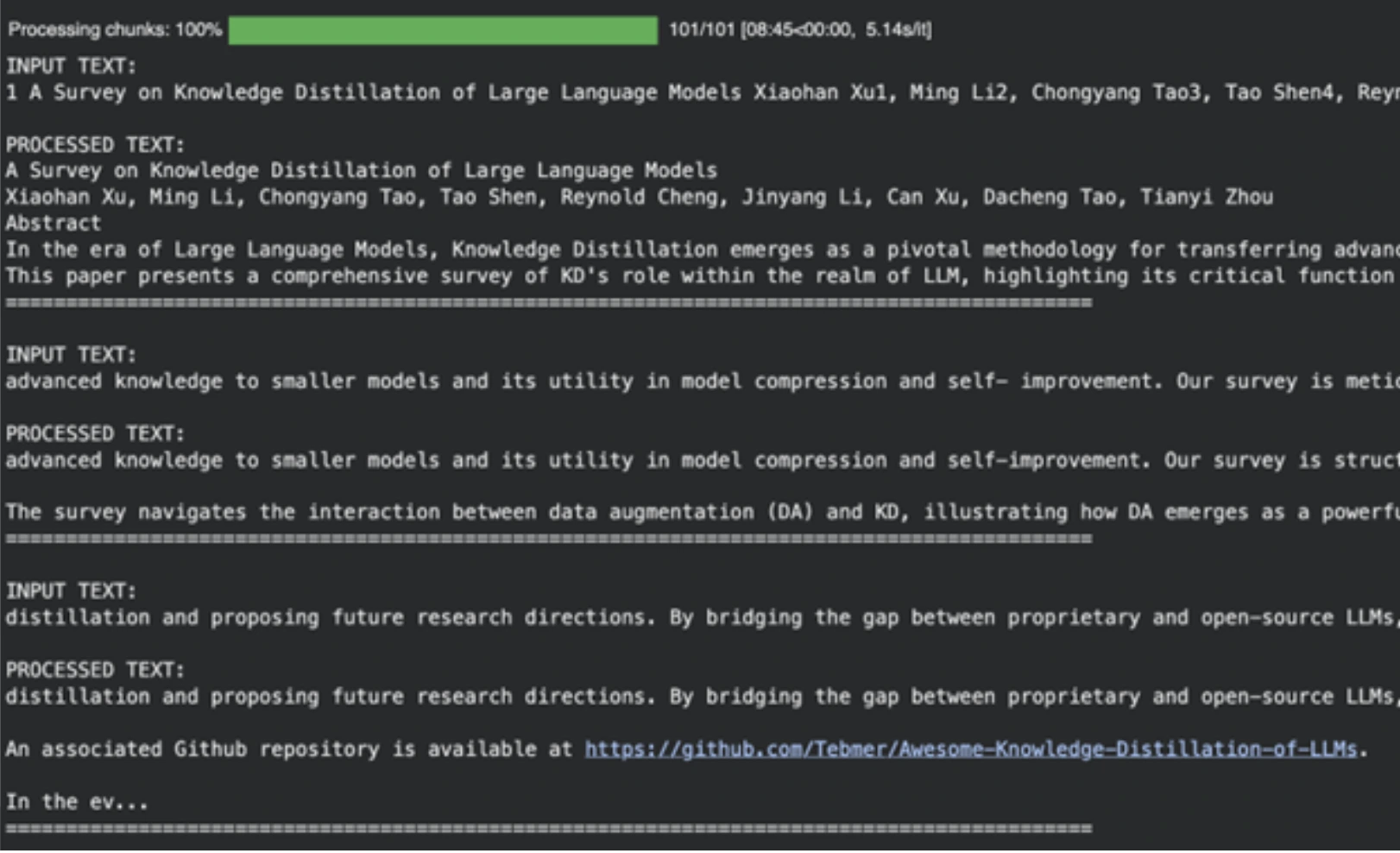
The mannequin is beneficial in eliminating tutorial references, formatting rubbish, and different non-useful content material and making ready it as enter to the subsequent part of our AI-powered podcast manufacturing.
NOTE: Please head over to this Colab Pocket book for a full code: Step-1 PDF-Pre-Processing-Logic.ipynb
Step 3: Podcast Script writing.
With clear textual content, we will now generate the podcast script. On this inventive job, we take a stronger mannequin, which is llama-3.3-70b-versatile. We’ll immediate it to create a dialog between two audio system.
Outline the Scriptwriter Immediate
This immediate system is a extra detailed one. It defines the roles of Speaker 1 (the professional) and Speaker 2 (the curious learner). It promotes a pure, energetic dialogue with interruptions and analogies.
SYSTEM_PROMPT = """
You're the a world-class podcast author, you will have labored as a ghost author for Joe Rogan, Lex Fridman, Ben Shapiro, Tim Ferris.
We're in an alternate universe the place really you will have been writing each line they are saying they usually simply stream it into their brains.
You may have received a number of podcast awards in your writing.
Your job is to write down phrase by phrase, even "umm, hmmm, proper" interruptions by the second speaker based mostly on the PDF add. Hold it extraordinarily participating, the audio system can get derailed every now and then however ought to focus on the subject.
Keep in mind Speaker 2 is new to the subject and the dialog ought to all the time have practical anecdotes and analogies sprinkled all through. The questions ought to have actual world instance comply with ups and so forth
Speaker 1: Leads the dialog and teaches the speaker 2, provides unimaginable anecdotes and analogies when explaining. Is a fascinating instructor that offers nice anecdotes
Speaker 2: Retains the dialog on monitor by asking comply with up questions. Will get tremendous excited or confused when asking questions. Is a curious mindset that asks very fascinating affirmation questions
Be sure that the tangents speaker 2 supplies are fairly wild or fascinating.
Guarantee there are interruptions throughout explanations or there are "hmm" and "umm" injected all through from the second speaker.
It needs to be an actual podcast with each high-quality nuance documented in as a lot element as potential. Welcome the listeners with a brilliant enjoyable overview and hold it actually catchy and virtually borderline click on bait
ALWAYS START YOUR RESPONSE DIRECTLY WITH SPEAKER 1:
DO NOT GIVE EPISODE TITLES SEPARATELY, LET SPEAKER 1 TITLE IT IN HER SPEECH
DO NOT GIVE CHAPTER TITLES
IT SHOULD STRICTLY BE THE DIALOGUES
"""Generate the Transcript
The clear textual content of the earlier step is shipped to this mannequin. The mannequin will yield a full-size podcast transcript.
# Learn the cleaned textual content
with open("clean_extracted_text.txt", "r", encoding="utf-8") as file:
input_prompt = file.learn()
# Instantiate the bigger mannequin
chat = ChatGroq(
temperature=1,
model_name="llama-3.3-70b-versatile",
max_tokens=8126,
)
messages = [
SystemMessage(content=SYSTEM_PROMPT),
HumanMessage(content=input_prompt),
]
# Generate the script
outputs = chat.invoke(messages)
podcast_script = outputs.content material
# Save the script for the subsequent step
import pickle
with open("information.pkl", "wb") as file:
pickle.dump(podcast_script, file)Output
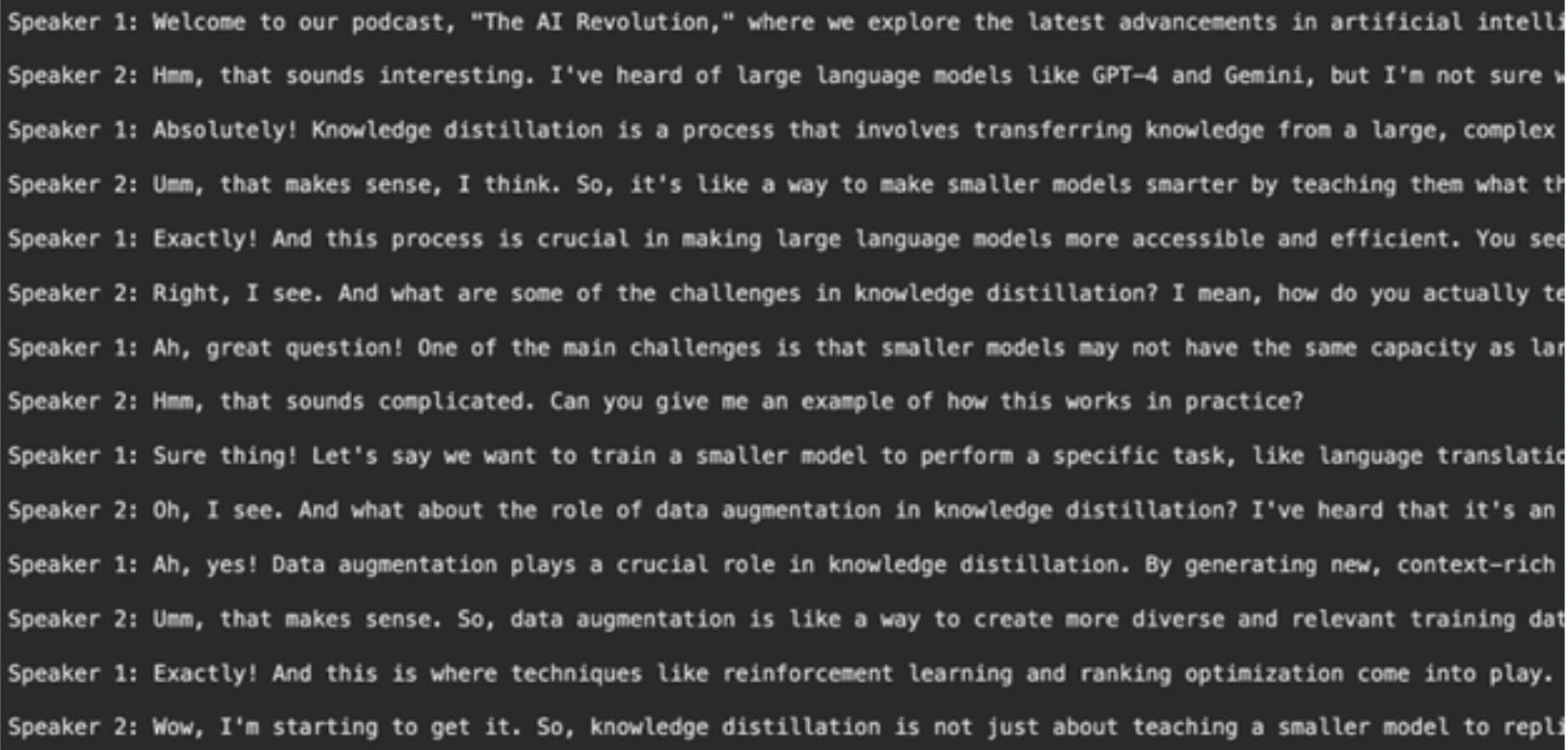
NOTE: You’ll find the total and executable Colab pocket book for this step right here:
Step-2-Transcript-Author.ipynb
Step 4: Rewriting and Finalizing the Script
The script that’s generated is okay, although it may be improved to sound extra pure when producing text-to-speech. The fast rewriting job can be completed utilizing Llama-3.1-8B-On the spot. The important thing intention of that is to format the output within the preferrred case for our audio technology performance.
Outline the Rewriter Immediate
This request requires the mannequin to carry out the position of a screenwriter. Proof One in all these directions is to retailer the ultimate lead to a Python record of tuples type. The tuples will include the speaker and the dialogue of the speaker. It’s easy to course of on this construction within the final step. We additionally embody sure particulars on how one can pronounce such phrases of the speaker, equivalent to “umm” or “[sighs]” to be extra practical.
SYSTEM_PROMPT = """
You might be a world oscar winnning screenwriter
You may have been working with a number of award profitable podcasters.
Your job is to make use of the podcast transcript written under to re-write it for an AI Textual content-To-Speech Pipeline. A really dumb AI had written this so it's a must to step up in your sort.
Make it as participating as potential, Speaker 1 and a couple of can be simulated by totally different voice engines
Keep in mind Speaker 2 is new to the subject and the dialog ought to all the time have practical anecdotes and analogies sprinkled all through. The questions ought to have actual world instance comply with ups and so forth
Speaker 1: Leads the dialog and teaches the speaker 2, provides unimaginable anecdotes and analogies when explaining. Is a fascinating instructor that offers nice anecdotes
Speaker 2: Retains the dialog on monitor by asking comply with up questions. Will get tremendous excited or confused when asking questions. Is a curious mindset that asks very fascinating affirmation questions
Be sure that the tangents speaker 2 supplies are fairly wild or fascinating.
Guarantee there are interruptions throughout explanations or there are "hmm" and "umm" injected all through from the Speaker 2.
REMEMBER THIS WITH YOUR HEART
The TTS Engine for Speaker 1 can't do "umms, hmms" properly so hold it straight textual content
For Speaker 2 use "umm, hmm" as a lot, you may as well use [sigh] and [laughs]. BUT ONLY THESE OPTIONS FOR EXPRESSIONS
It needs to be an actual podcast with each high-quality nuance documented in as a lot element as potential. Welcome the listeners with a brilliant enjoyable overview and hold it actually catchy and virtually borderline click on bait
Please re-write to make it as attribute as potential
START YOUR RESPONSE DIRECTLY WITH SPEAKER 1:
STRICTLY RETURN YOUR RESPONSE AS A LIST OF TUPLES OK?
IT WILL START DIRECTLY WITH THE LIST AND END WITH THE LIST NOTHING ELSE
Instance of response:
[
("Speaker 1", "Welcome to our podcast, where we explore the latest advancements in AI and technology. I'm your host, and today we're joined by a renowned expert in the field of AI. We're going to dive into the exciting world of Llama 3.2, the latest release from Meta AI."),
("Speaker 2", "Hi, I'm excited to be here! So, what is Llama 3.2?"),
("Speaker 1", "Ah, great question! Llama 3.2 is an open-source AI model that allows developers to fine-tune, distill, and deploy AI models anywhere. It's a significant update from the previous version, with improved performance, efficiency, and customization options."),
("Speaker 2", "That sounds amazing! What are some of the key features of Llama 3.2?")
]
"""Generate the Ultimate, Formatted Transcript
On this mannequin, we load the script of the final step and feed it to the Llama 3.1 mannequin utilizing our new immediate.
import pickle
# Load the first-draft script
with open("information.pkl", "rb") as file:
input_prompt = pickle.load(file)
# Use the 8B mannequin for rewriting
chat = ChatGroq(
temperature=1,
model_name="llama-3.1-8b-instant",
max_tokens=8126,
)
messages = [
SystemMessage(content=SYSTEM_PROMPT),
HumanMessage(content=input_prompt),
]
outputs = chat.invoke(messages)
final_script = outputs.content material
# Save the ultimate script
with open("podcast_ready_data.pkl", "wb") as file:
pickle.dump(final_script, file)Output

NOTE: Please discover the total executable code for this step right here: Step-3-Re-Author.ipynb
Step 5: Producing the Podcast Audio.
We now possess our last-looking script, made up. It’s time now to translate it to audio. The mannequin that we’re going to use to generate text-to-speech of top quality is Groq playai-tts.
Arrange and Check Audio Technology
First, we set up the mandatory libraries and arrange the Groq shopper. We will take a look at the audio technology with a easy sentence.
from groq import Groq
from IPython.show import Audio
from pydub import AudioSegment
import ast
shopper = Groq()
# Outline voices for every speaker
voice_speaker1 = "Fritz-PlayAI"
voice_speaker2 = "Arista-PlayAI"
# Check technology
textual content = "I like constructing options with low latency!"
response = shopper.audio.speech.create(
mannequin="playai-tts",
voice=voice_speaker1,
enter=textual content,
response_format="wav",
)
response.write_to_file("speech.wav")
show(Audio("speech.wav", autoplay=True))Generate the Full Podcast
At this level, we load our final script, which is a String manifestation of an inventory of tuples. So as to safely revert it to an inventory, we do it with ast.literaleval. Then we run each line of dialog by way of it, create an audio file of it and fix it to the podcast voice-over on the finish.
One other type of error dealing with that’s applied on this code is to take care of API charge limits, that are a standard phenomenon in sensible purposes.
import tempfile
import time
def generate_groq_audio(client_instance, voice_name, text_input):
temp_audio_file = os.path.be a part of(
tempfile.gettempdir(), "groq_speech.wav"
)
retries = 3
delay = 5
for i in vary(retries):
strive:
response = client_instance.audio.speech.create(
mannequin="playai-tts",
voice=voice_name,
enter=text_input,
response_format="wav",
)
response.write_to_file(temp_audio_file)
return temp_audio_file
besides Exception as e:
print(f"API Error: {e}. Retrying in {delay} seconds...")
time.sleep(delay)
return None
# Load the ultimate script information
with open("podcast_ready_data.pkl", "rb") as file:
podcast_text_raw = pickle.load(file)
podcast_data = ast.literal_eval(podcast_text_raw)
# Generate and mix audio segments
final_audio = None
for speaker, textual content in tqdm(podcast_data, desc="Producing podcast segments"):
voice = voice_speaker1 if speaker == "Speaker 1" else voice_speaker2
audio_file_path = generate_groq_audio(shopper, voice, textual content)
if audio_file_path:
audio_segment = AudioSegment.from_file(
audio_file_path, format="wav"
)
if final_audio is None:
final_audio = audio_segment
else:
final_audio += audio_segment
os.take away(audio_file_path)
# Export the ultimate podcast
output_filename = "final_podcast.mp3"
if final_audio:
final_audio.export(output_filename, format="mp3")
print(f"Ultimate podcast audio saved to {output_filename}")
show(Audio(output_filename, autoplay=True))Output

This last step completes our PDF-to-podcast pipeline. The output is a completely full audio file that’s to be listened to.
NOTE: You’ll find the colab pocket book for this step right here: Step-4-TTS-Workflow.ipynb
The next are the order-wise Colab pocket book hyperlinks for all of the steps. You may re-run and take a look at NotebookLlama by yourself.
- Step-1 PDF-Pre-Processing-Logic.ipynb
- Step-2-Transcript-Author.ipynb
- Step-3-Re-Author.ipynb
- Step-4-TTS-Workflow.ipynb
Conclusion
At this level, you will have created a complete NotebookLlama infrastructure to rework any PDF right into a two-person podcast. This process demonstrates the power and flexibility of the present-day open supply AI fashions. Clustering collectively numerous fashions alongside the implementation of sure duties, equivalent to a tiny and fast Llama 3.1 to wash and a much bigger one to provide content material, enabled us to create an environment friendly and efficient pipeline.
This audio podcast manufacturing method is extraordinarily tailorable. You may alter the prompts, choose numerous paperwork or change different voices and fashions to provide distinctive content material. So go forward, give this NotebookLlama venture a strive, and tell us the way you prefer it within the feedback part under.
Ceaselessly Requested Questions
A. Even the context may be understood by AI fashions, making them more proficient at coping with combined and unexpected format issues in PDFs. It won’t contain as a lot handbook work because the writing of intricate guidelines.
A. Sure, this pipeline can be utilized with any text-based PDF. Change the specified file as step one by coming into the PDF path of the file.
A. Easy duties equivalent to cleansing take much less time and fewer price on a small and quick mannequin (Llama 3.1 8B). When doing inventive assignments, equivalent to scriptwriting, now we have a much bigger, extra competent typewriter (Llama 3.3 70B) to create higher work.
A. Information distillation is a synthetic intelligence technique wherein a smaller mannequin, known as a scholar, is skilled with the assistance of a bigger, stronger, so-called instructor mannequin. This assists within the formation of efficient fashions that work successfully in sure duties.
A. Within the case of actually massive paperwork, you would need to apply a extra refined processing logic. This may increasingly embody summarising each chunk to ship to the scriptwriter or a sliding window scheme to hold throughout chunks.
Login to proceed studying and revel in expert-curated content material.